Achieving Multiple Routing Keys in RabbitMQ Exchanges
Update: this post was originally published in November 2017 but has been updated with the latest information and changes as of March 2024.
A key feature inside RabbitMQ is the ability to easily route messages between exchanges and queues, using any number of provided routing algorithms. The server plays a centric role in message routing, keeping this logic outside of your application. While this provides a good level of abstraction, sometimes you need more control over which messages go where. This is what we'll be investigating throughout this post.
Problem Space
For a moment let's consider an architecture in which your producer is sending messages to specific consumers, rather than simply emitting messages for anyone to pick up. This is the use case with which I have been working recently (albeit a little simplified). To set some basic requirements as context for the rest of this post, we'll assume that:
- Each message is to be routed to any number of consumers (or none at all)
- Each consumer will only receive at most a single copy of a message
- The set of consumers is known in some form by the producing service
These requirements are quite straightforward, but as we'll find out shortly it's not exactly intuitive as to the best way to satisfy these constraints. RabbitMQ generally encourages routing to be managed by the server itself, with a focus on keeping routing logic out of producing services (and the AMQP itself).
On the whole this is pretty good advice as it reduces complexity by offloading routing logic to RabbitMQ, which in theory has been strongly tested for correctness before you even come to use it. With that being said, there are times when you already have RabbitMQ inside your technology stack and being able to use it for something like this is both practical and cost-effective.
RabbitMQ's Toolbox
RabbitMQ includes a variety of options and routing algorithms out of the box, some which are based on the AMQP and some which are extensions to the protocol. A lot of these extensions are covered in the official RabbitMQ documentation on message routing.
Exchanges are AMQP 0-9-1 entities where messages are sent to. Exchanges take a message and route it into zero or more queues. The routing algorithm used depends on the exchange type and rules called bindings.
Some of these built-in exchange types are pretty relevant for potentially solving our use case. At a quick glance over the documentation above it looks like these exchange types might be a good fit for us:
- Direct routing key matches (key="key")
- Header based matching (headers["field"]="value")
- Pattern based routing key matches (key="brown.owl", pattern="*.owl")
By having access to each of these exchange types you gain the ability to cover a broad range of architectures and messaging patterns. We'll look at each of these implementations and examine exactly where they do and do not fit our requirements - hopefully in a way that makes it clear as to which use cases they could fit and definitely do not fit.
Topic Exchanges - Pattern Based Routing
After initially reading through the RabbitMQ
blog posts
about their improvements to topic based routing, it seemed that our use case could be quickly solved
by using a simple
topic exchange
setup. To briefly summarize the main aspects of a topic exchange:
- Messages are produced with a routing key containing a topic
-
Each topic is a pattern of dot-separated keys in the form
x.y.z -
Keys can be literal strings, or you can use wildcards
- You can use the
#character to mean zero or more keys - You can use the
*character to mean exactly one key
- You can use the
- You can use any number of keys within a topic
To hopefully represent some of this information in a more visual way, all of the following values are
valid and matching topics for messages sent through a topic exchange with a routing key of
a.b.c:
a.b.c
a.*.c
a.b.*
*.b.*
*.*.c
*.*.*
#.a.#
#.b.*
#.b.c
#.c
#
You should be able to see that this is clearly an extremely powerful form of routing, and should be
able to represent a wide variety of use cases using these patterns. To apply these patterns to our use
case, it's possible to add a simple binding (#.<consumer>.#) to a topic exchange
which will then locate your consumer when a routing key contains consumer names
(consumer1.consumer2.consumer3).
Some quick prototyping demonstrates that this works as expected and does indeed fit our requirements. Unfortunately though, as ever, it's not that easy. Topic exchanges come with some serious downsides with regards to performance. As with most (all?) pattern matching algorithms, use of wildcares inside topics is pretty slow - especially when they're at the start of the topic:
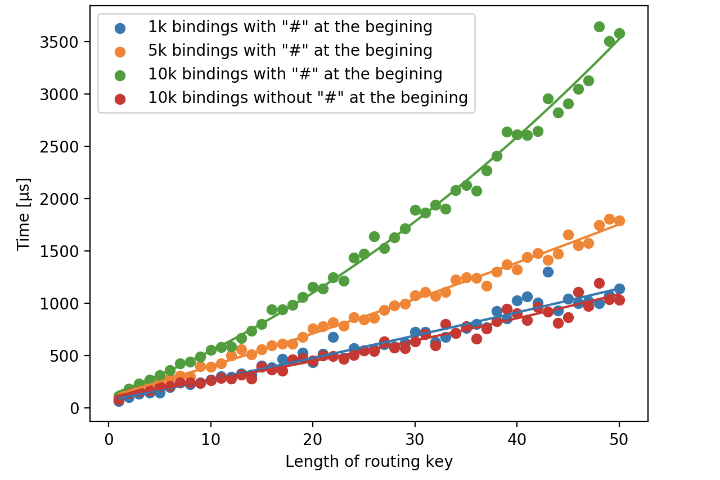
Rather than going too deep into this here, there is a fantastic write up over at Erlang Solutions on understanding topic exchanges if you're more interested in how they work under the hood. The image above is embedded from this post and showcases the issues you can have with scaling leading wildcards to a wider set of bindings.
After testing my prototype implementation with the rabbitmq-perf-test project, unfortunately this turned out to be a dealbreaker (numbers at the end of this post). Topic exchanges may still be viable if you're only planning on a small numbers of bindings, however my case revolves around bindings which are both dynamic and unbounded. This results in the slowdown here being too great to be a viable option.
Headers Exchanges - Property Based Routing
Another powerful exchange type offered to us is the
headers exchange. Each message sent through RabbitMQ can have arbitrary headers attached to them. Headers can be
thought of as a map of key/value properties (of various types), which can then be used for routing via
the headers exchange.
Binding on a headers exchange allows you to match messages based on either all of the headers, a
subset of their headers, or a mixture of both (via multiple bindings). A very naive implementation of
our use case using a headers exchange could use our consumer identifiers as field names in the
headers, with a value of true and then simply test for presence. In JSON, this could look
something like this:
{
// ...
"headers": {
"consumer1": true,
"consumer2": true,
"consumer3": true
// ...
}
}
We can use this concept to bind to our exchange using our consumer name as an argument to the binding,
specifically in the form of consumer2=true to represent that we're interested in messages
designated for our consumer. This appears to function as expected, and appears to be much faster than
our implementation using topic exchanges. However that doesn't mean that we have found our ideal
solution!
A headers exchange has to do a lot of work when matching headers, in particular because this key/value mapping is stored as a list of pairs within Erlang. A lookup of a header must walk through the headers list in order to find the value associated with it - and of course this performance overhead still applies even if your specified header is not present.
What's more, it's not possible to effectively cache these lookups and it's therefore repeated for each binding against your exchange. This means that having 100 bindings on a headers exchange will cause the message headers to be walked 100 times, even if the result is that the message matches none of them. If you're interested you can see the current implementation here (which I pinned at the time of writing).
The result of the investigation here is much like that of the topic exchange; functionally it may be a good fit, but the performance impact and potential concerns when scaling the number of bindings mean that we need to continue looking for alternatives.
Direct Exchanges - Key Based Routing
If you're familiar with the different exchange types of RabbitMQ, you may have realised that we really
only need a
direct exchange
which includes supports multiple routing keys per message. The default direct exchange
only allows for a single routing key, which means that it's not possible for us to express that a
message should be routed to more than one consumer. This means that we it's possible to implement our
logic by producing messages in a (pseudocode) loop:
// create our direct exchanges
let exchange = createDirectExchange();
// calculate our consumers list
let consumers = getConsumersForMessage(payload);
// publish a copy for each consumer
for (let consumer of consumers) {
exchange.publish({
routing_key: consumer,
content: payload
});
}
This is extremely basic, but works! The clear downside is that we're producing N copies
of a message inside RabbitMQ where N matches the number of consumers being routed to.
This is obviously both expensive and slow. That being said it will definitely serve our use case with
a pretty simple implementation.
We can do better than this, though! RabbitMQ ships with various extensions on top of AMQP and one of them in particular is relevant to what we're trying to do here: Sender Selected Distribution. This is covered in more depth during the announcement post but in essence this extension changes the dynamic of routing to act more like an email:
- The routing key is somewhat similar to the recipient of an email
- We can provide a header named
CCwhich includes a list of secondary routing keys -
We can also provide a header named
BCCwhich includes a list of tertiary routing keys - The
BCCheader is stripped out before being passed to consumers - Note that
CCandBCCheaders are case sensitive
With this new paradigm we can now refine our naive implementation to be more performant. These changes will combine our multiple calls to RabbitMQ into a single call, and ensure that we only produce a single copy of our message:
// create our direct exchanges
let exchange = createDirectExchange();
// calculate our consumers list
let consumers = getConsumersForMessage(payload);
// publish a copy for each consumer
my_exchange.publish({
routing_key: consumers[0],
headers: {
CC: consumers[1:]
},
content: payload
});
This solution looks pretty good! We have eliminated most of our naive performance hit, and it fits our
use case and criteria. It's also pretty easily understandable due to making use of terms we're all
familiar with from the world of email. Even though the implementation of CC and
BCC does have to walk the headers list, much like the implementation in the headers
exchange, the major difference is that it's a single lookup (of each header) rather than one for each
binding on your exchange.
As this is the last option available to use which ships alongside RabbitMQ (that I know of), I would recommend taking this approach if you're looking for something out of the box. The performance hit does exist, but it's low enough that the convenience of this functionality being readily available should likely offset it for most engineering decisions. With that being said, there is still one more option available to us in the next section.
One last note here: if you're only producing a message for a single consumer, it is better to
simply omit the CC or BCC header rather than including an empty list. This
will skip lookups of these headers completely if your headers list is empty, and improve performance
of other header lookups in RabbitMQ due to the list being one element shorter.
Delimiter Exchanges - Split Based Routing
Beyond the exchange types that ship with RabbitMQ, we are also able to create our own custom types through the use of the RabbitMQ plugin system. When looking at the usage of a direct exchange above, it's clear that it would be preferable if we were able to express the same semantics whilst also not having to touch the message headers.
When looking deeper into RabbitMQ, it turns out that their message model actually already supports a
list of routing keys rather than a single string. I assume this is related to supporting things like
CC and BCC without having to have a totally separate message flow for those.
This has the happy side effort that most of their existing exchange implementations and utilities
also already support multiple routing keys in their implementation; it's simply that AMQP
itself does not allow passing multiple keys alongside a message.
For us, this means that our goal is now figure out how we can express multiple keys from within a
single routing key. One of the more common ways to represent multiple values within a string is the
separation of values using a delimiter (for the sake of example, let's use
:). This is somewhat similar to the topic exchange above, where . is the
delimiter between each consumer, and results in routing keys taking this form:
consumer1:consumer2:consumer3.
Our custom exchange can then separate the routing key based on the : delimiter, and then
pass the new list of routing keys into the existing direct routing algorithm and
everything will be routed exactly as we need. To make this approach a little more flexible, we can
also turn this into a self-describing implementation by using the first character in the routing key
as the delimiter for the rest of the key. In this case our routing key turns into
:consumer1:consumer2:consumer3.
This all seems pretty promising, so I decided I decided to turn this into a RabbitMQ plugin as a
learning experience. It was fairly simple to wrap something around the existing
direct exchange implementation, and this is how the
x-delimiter-exchange
came into being. This plugin can be installed in your RabbitMQ cluster to provide a way to use
multiple routing keys alongside a message with a low overhead.
Update 2024: it looks like as of RabbitMQ v3.13 there is no longer any meaningful difference
between the use of x-delimiter exchanges and the CC header inside a
direct exchange. Please see the benchmarking results below for more detail.
Performance Comparisons
As I mentioned earlier in this post, I tested each of these approaches using the official rabbitmq-perf-test tool. These numbers differ heavily based on your usage pattern and version of RabbitMQ, so make sure to read through each test individually to locate the one which fits your traffic best. To avoid cluttering this post with lots of extra information, each of these tests will produce messages as follows:
| Type | Binding Definition | Message Properties |
|---|---|---|
| direct | <consumer> | key = consumers[0], headers = { CC: [consumers[1:] } |
| headers | <consumer>=true | key = "", headers = { <consumer>: true, ... } |
| topic | #.<consumer>.# | key = consumers.join(".") |
| x-delimiter | <consumer> | key = ":" + consumers.join(":") |
You can use this table to refer to when looking how to define your message for each of the exchanges.
The key value is obviously the routing key, and the headers value is how
headers will be created for each test. To keep things simple each of my consumers will be named
consumerX where X is just the number of the consumer, so
C2 will be named consumer2. Each of the tests will be defined in the form of
<produced-for>:<consumed-by>, with five sets of benchmarks being covered:
C1-3:C2C1-3:C1-3C1-10:C2C1-10:C8C1-10:C1-10
Messages will be "produced for" a set of consumers by being published with the appropriate
keys/headers to route to those consumers. Only a specific subset of consumers will actually have
queues bound, to test how exchanges scale across bindings. I chose not to test
C1:C1 given this use case would generally just use a standard direct exchange. The
results of these tests are as follows, updated as of March 2024:
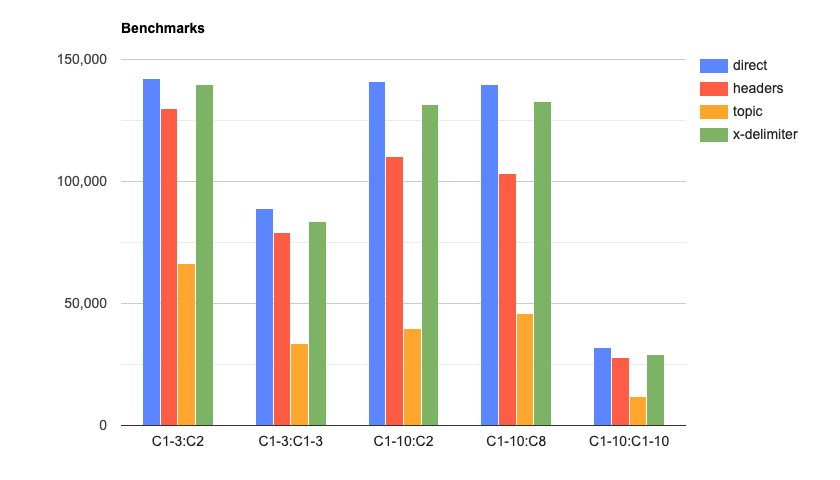
These updated numbers now clearly show that using a direct exchange alongside the
CC header is the way to go (as of RabbitMQ v3.13). In earlier versions of RabbitMQ the
x-delimiter exchange performed much more effectively, but this appears to no longer be
the case - likely due to the performance optimizations and internal refactoring as part of
RabbitMQ v3.13.
Worth noting is that the difference in the performance of headers exchanges for tests
C1-10:C2 and C1-10:C8. Comparing headers in RabbitMQ involves walking a map
via a list of key/value pairs. These pairs are presumably sorted at some point, and so a header which
appears later alphabetically will perform a little slower on average. The difference is not
huge but it's definitely noticeable, so it's something to keep in mind!
Final Thoughts
As ever, make sure to benchmark on your own hardware with your own use cases to determine the option
you should go with. Based on the benchmarks above, you should probably be using
direct exchanges alongside the CC header as of RabbitMQ v3.13. Earlier
versions will likely still see benefit when using x-delimiter exchanges (which I have
been using in production environments since approximately RabbitMQ v3.6). Even if these exchanges are
faster, you may appreciate not having to install a custom plugin into your RabbitMQ environment - it
definitely is a bit annoying.
If you do decide to try out the x-delimiter exchange, you can find it on the
GitHub repository
whitfin/rabbitmq-delimiter-exchange
along with instructions and releases on how to install it inside your cluster. The actual code is
tiny due to the re-use of RabbitMQ's internal tooling, making it easy to both test and audit.
I hope you found this post helpful and/or interesting, I definitely learned a lot while researching
the content - thank you for reading!